
Note: The automation tool referenced below was created from the great work and by our skillful Automation Engineering team
Yeah, it can be, if this is the first time that you are considering the implementation of test automation in your software project, the evaluation process and deployment of the solution could become a nightmare. There are many unknowns and with the number of techniques and tool options available, it is easy to go down the wrong path. Or maybe your team does not have the necessary skills to build an automation framework from scratch, in the end, a mistake in this area could easily impact your expected ROI. Important considerations include – which language should you use, should you try with an open-source or a proprietary one? what about reports? Parallel executions? Or loggers, what if you need to use data-driven testing?
We developed a Software QA automation accelerator tool, that helps our clients successfully address the above challenges as part of our client engagements. It has proven success in multiple web-based automation projects, and it has been implemented using both Java and C# , based on client’s platform requirements. One of the strengths of our framework is that the stack of tools used is all open source, meaning no incremental charges for third party licenses when implementing your automated test cases.
How do we accelerate the automation process?
It is simple, based on our experience of working on previous projects, we realized that every web automation solution is following a common pattern of functionality that must be present for the solution to be robust, reliable and useful. So, we took those basic units and included the implementation in our framework. Let’s describe it:
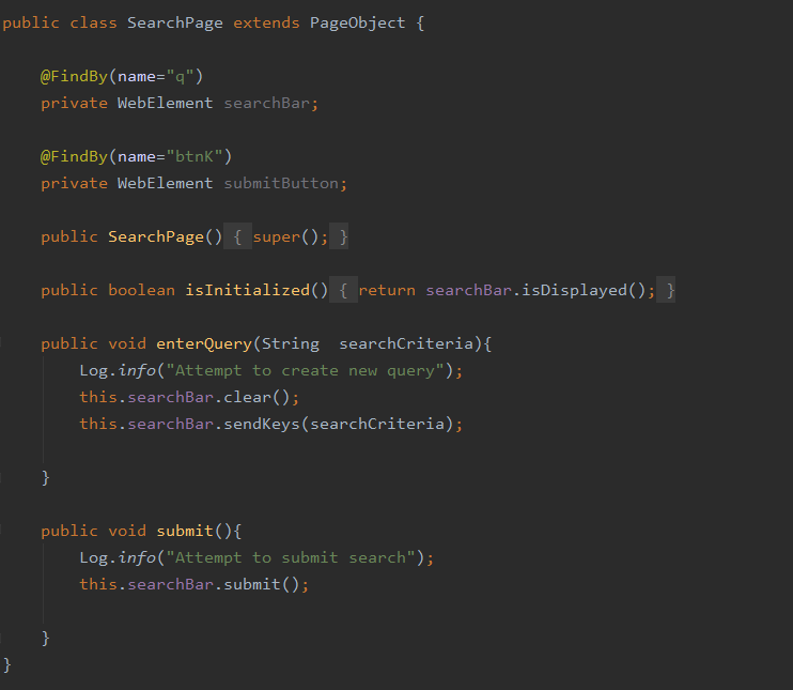
Selenium, by far it has become the standard framework for automation. It is open source, with huge support from the technology community and constant updates made to the framework. With Selenium as the foundation, we use the Page Object pattern, an industry standard that creates an object for each page assessed in the test cases. This helps with the encapsulation of the implementation and improves the quality of the test case classes – since they will be focused on the test “stimulus”, and not the interaction with the selenium driver.
In the following image, you can see an example of a functional Page Object with the useful web elements from the page and the actions that can be executed with them.
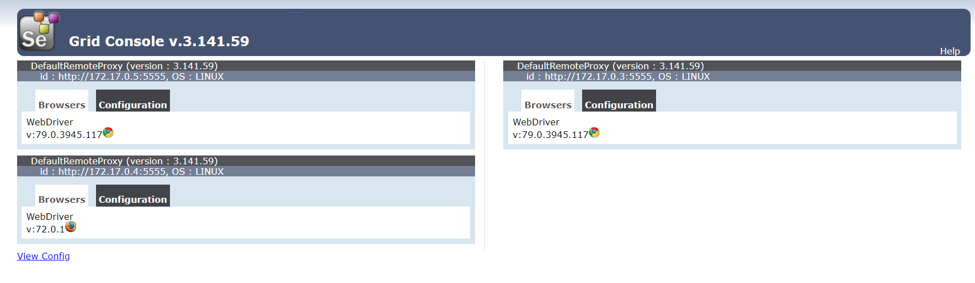
With selenium the implementation of Selenium Grid is essential, selenium grid is a tool that allows you to execute multiple instances of browsers on the same machine at the same time. This allows parallel execution, thus reducing the entire execution time of the suite. In some cases, selenium grid was executed using a virtual machine, but there is often a problem with this approach – it can consume significant resources from the host machine and sometimes the virtual machine stalls or is in an invalid state – negatively impacting execution. As a solution to this problem we often implement the selenium grid in docker instances. Docker is a virtualization tool that creates containers, you can create as many containers as you want and as the host can support. Each container is the host of a single browser driver, which allows us to execute the test cases in parallel. The main benefit from Docker compared to virtual machines is that if at some point something fails you can stop the failing container and create a new one within minutes. In the following image, you can see a selenium grid instance with 2 chrome browsers and one Firefox browser.
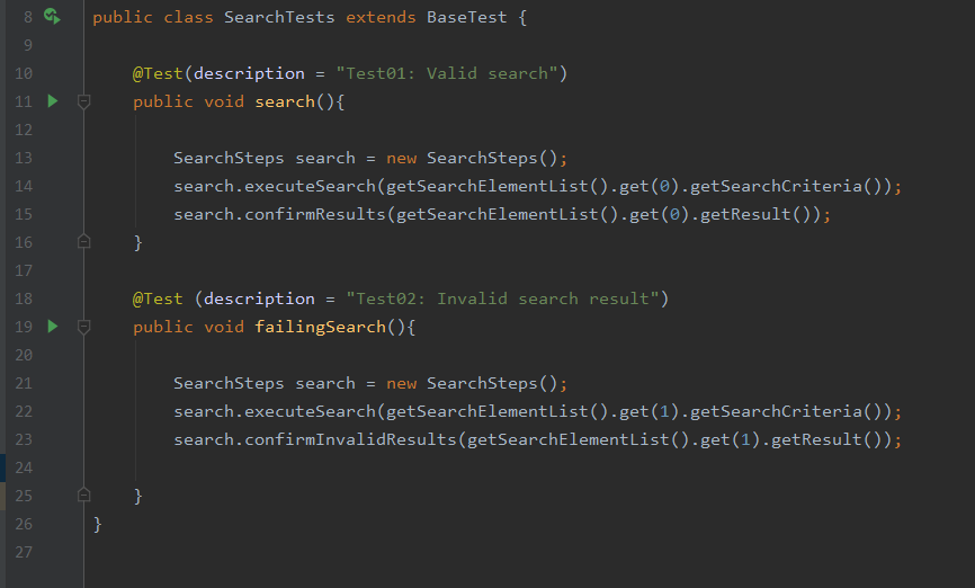
Normally, there are test cases that basically share the same steps but differ on the input data. The typical way to automate them is to create one test case for each scenario and copy and paste the steps, but this is inefficient and difficult to maintain. Instead, we use a data-driven approach, that basically means that we reuse the same steps for all the scenarios, but the input stimulus data will come from a .json file. This is much easier to maintain and generates a high level of flexibility for the implementation of new test cases. Instead of creating new steps you only add valid stimulus in the input file and apply it accordingly. In the following image you can see a simple example of two test cases with data-driven testing:
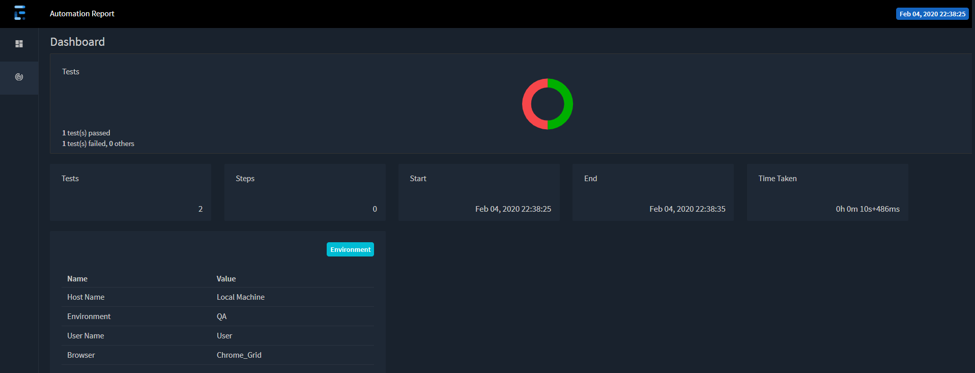
You can have the best automation framework that never fails and finds multiple bugs, but if you are not capable of effectively sharing the results, then the framework is of no used to the business. Which is why we have included Extent Reports in the accelerator, that shows in a very user-friendly way how the execution job performed, how many test cases passed, were idle, or failed, For failed cases, a screenshot of the last screen that was seen at the moment of the error is attached. The reports include the time, user, operating system and details of the machine where they were executed. In the following images, you can see examples of the automation report.
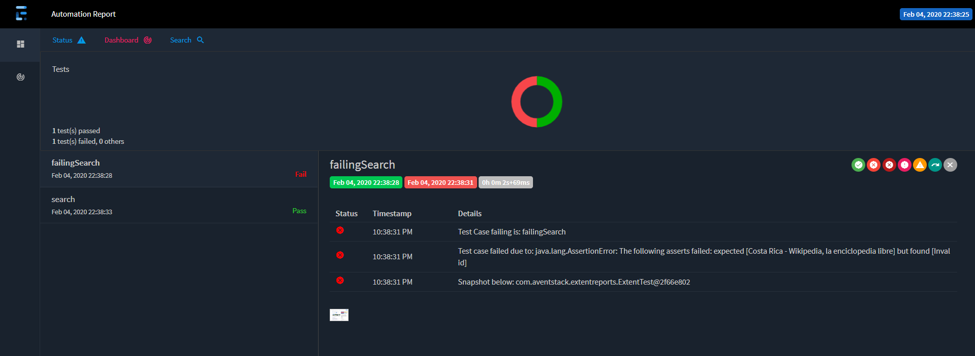
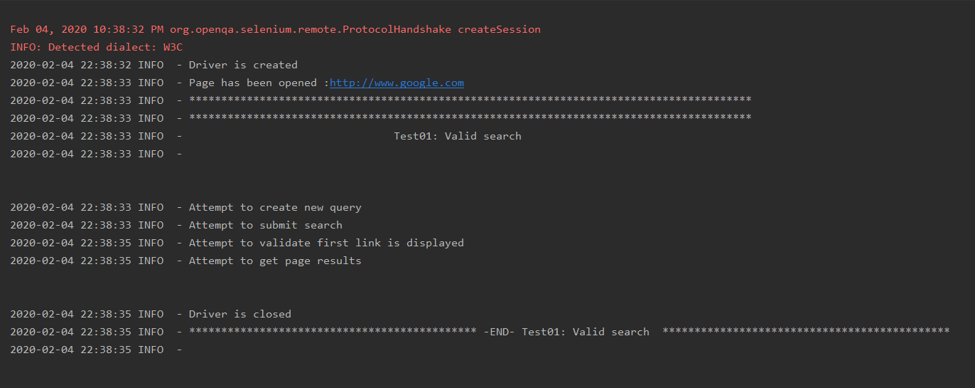
Also included is logger (a best practice in automation), it is useful because it will note every action where the driver interacted with the web page. This allows the user to understand what happened in real-time with the test case, and in case of failures – easily see the last successfully command that was executed , allowing debugging to begin from there. In the following image, you can see a small example of the details that the logger prints for one specific test case:
We are also working on the development of an automation accelerator for mobile platforms using Appium as the mobile framework, this one will include all the features described above in order to reduce the time for automation.


 SIgn up
SIgn up